フクロウ小路と人のいう
こんにちわ。こんばんわ。かえるのクーの助手の「井戸中 聖」(いとなか セイ)でございます。


どこに進んでいるのかまったくわからない状態になってしまいました。
 ねぇ人生ってなんだろうね?さぁ。
ねぇ人生ってなんだろうね?さぁ。
連休は3日目に突入しましたが、昨日から学習がうまくすすみません。意図せず報酬が矛盾しているのかもしれません。
一旦報酬をリセットして通常学習させたあと、追加した報酬でさらに強化学習する方向にしたいと思います。
夜は停電しないと思うので。。。
この部屋はクーラーがないのと、パソコンの発熱で地獄の様相です。
こらぁ。ぼーる蹴れーーー!
 個人技は超絶うまいのに、パスを出せないレントン少年。
個人技は超絶うまいのに、パスを出せないレントン少年。
オウンゴールを責めたので、しまいに誰もボールを蹴らなくなりました。ボールに近づくのもイヤみたいです。
やっぱり、強化学習は褒めて伸ばす方向じゃないとダメみたいですね。
叱る(マイナス報酬)はとても難しいと感じました。
ブチ切れる(オウンゴールで-10.0)のではなく、諭す(オウンゴールで-0.1)ように修正して最初から学習しなおします。
そもそもディフェンスして触ったものの残念ながらオウンゴールと、自ら力いっぱい自分のゴールに蹴りこむのとは、同じオウンゴールでも全く異なります。
このあたりの報酬評価のロジックに検討が必要です。
オウンゴールを「あまり」叱らないようにしたら時間はかかりました(上記画像で7時間目くらいです)が、「のびのび」ボールを追いかけるようになりました!少年・少女はそれでいいんですよ。学習中の録画なので、動作は飛び飛びに見えてしまいます。あしからず。
攻撃、防御の基本動作は身につきつつあるので、それが完了したら戦略的な強化学習の段階にすすみます。
今日中に個性(戦略)が別の複数チーム作って対戦させるのはどうみても無理ぽです。
さて、学習中で時間があるのでプチ情報などを記載してみます。
私の好きな「報酬」に関するお話
最適化のAIの話題で『あるお店「ビール」と「おむつ」の売り場を隣にしたら、それぞれの売り上げが2倍近くになった』話は有名です。たとえ話、作り話とも実話をもとにしているともいわれます。
強化学習の「報酬」についても似たような逸話があります。これも有名なので聞かれた方もおいでかと思います。(AIの話題ではないです)
・ある地区の消防団で、出動回数が多くなった。団員から「こんなに忙しいなら、特別手当をだしてほしい」の声があがり、火災件数に応じた手当をだすようにした。
半年あと、この地区はどうなったでしょう。⇒【答え】火災件数が倍増した。ボヤ程度では急いで出動せず(ボヤ対応は手当外だった)、団員は火災が起きることを心待ちした。
これをうけ、その地区はどうしたでしょう。⇒【答え】手当は廃止し、逆に火災が発生しないことに対して報酬を出すことにした。団員は地域の火災予防・啓蒙活動に熱心になり、対応も劇的に早くなった。(ボヤは火災にカウントされない)⇒火災件数が実際に激減した。
「報酬(罰)」は本当に難しいです。
「残業」もよく考えれば、仕事ができない(遅い)人ほど「すくなくとも一時的には」儲かる報酬制度です。ML-Agentなら、必ず生産性向上に努める「ふり」だけして、手をぬいて仕事をして、クビにならない範囲で「残業代」をかせぐことでしょう。
習得済の学習状態を引き継いで学習を続行できる?
条件が整えば可能です。入力パラメータや学習対象自体が(微妙に)変わった場合はうまくいかないケースもあります。
学習中断/終了の続行は0日目の話題のとおり、学習バッチに --resume を追加すると続行可能です。
mlagents-learn config/poca/SoccerTwos.yaml --run-id=SoccerTwos01 --resume
学習結果は、resultsフォルダの中にrun-idで指定した名称のフォルダができ、この中に関連情報を含んだチェックポイントファイルと、ニューラルネットワーク情報本体のファイル(Yamlの名称.onnx:機械学習標準フォーマット)が保持されます。
この学習情報を「起点」に追加で学習していく場合は
mlagents-learn config/poca/SoccerTwos.yaml --run-id=SoccerTwos02 --initialize-from=SoccerTwos01
のようにします。
最初から全部てんこ盛りに報酬すると、学習が安定しないので、基礎を習得させたあと、習得させたいスキル(お互いじゃましないもの)に対して追加の報酬(罰)を与えていくのがよさげです。
cudaを使用する場合は、--torch-device=cuda:0を付け加えます。
ただし、ボトルネックがUnity側にあるので、それほどGPU負荷はあがりません。
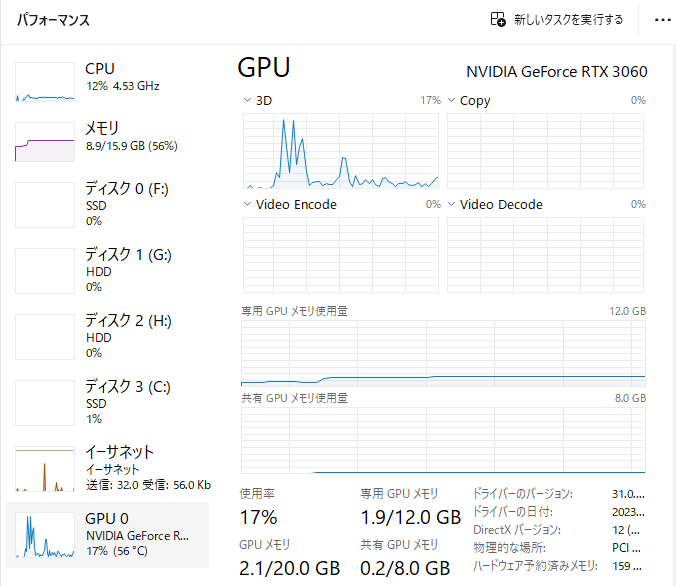
学習(トレーニング)が12時間(43200Sec)経過しました。

この学習内容の動作をみてみます。(あ!TensorFlowのグラフ確認をせずに終わってしまった。)
学習済のデータは指定IDのフォルダにSoccerTwos.onnxというファイルがあるので、これをサッカーのNNモデルのある\ml-agents\Project\Assets\ML-Agents\Examples\Soccer\TFModels フォルダに複写ます。mlagents-learnは起動せずにUnityのサッカーを起動すれば、学習済のファイル(SoccerTwos.onnx)を使ってAgentが動作します。
典型的なお団子サッカーで、サイドバーやゴール付近ではスクラムを組むラグビーのようにすら見える、力まかせの戦法になっています。攻撃(ボールを保持し、チャンスを待つ)と、防御(自陣に素早く戻り、壁をつくる)の基本はできているように思います。
ここからエレガントなパス回しや、ドリブルを強化学習により指導していくことは果たして可能なのでしょうか?
次のフェーズのトレーニング(想定では次の12時間程度)では、以下を考えてみます。
・ドリブルとロングパスの適切な評価(報酬)
・ゴールディフェンスの評価(決定機とディフェンスの判定)報酬
・オウンゴールについての賞罰を適切なものにする。(ディフェンスのうえでのオウンゴールは罰しない。自らのミスでのオウンゴールはもっと強い罰を与える)
エレガントな評価方法を考えよう(気分はサッカーチーム監督)
真面目に計算すればもちろん出来ますが、軽くて精度がそこそこある評価法を考えます。(案)
スルーパスを通す選手は好き
以下の条件のとき、スルーパス認定します。
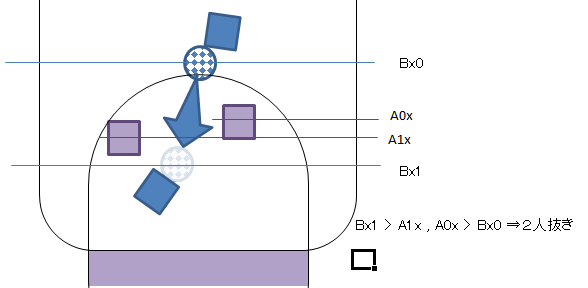
・自分がボールに触ったあと、味方がボールに触る。(パスが通る)
・味方がボールに触った位置が自分が触った位置よりもゴールに近い。
・パスを受けた時点・位置で、パス出し位置との間に1、もしくは2相手プレーヤがいる。(縦方向位置でのみ判定)
・2プレーヤーを抜いてパスが通れば高報酬とする。
・オフサイドは考慮なし
ドリブルで剥がす選手はかっこいい
・ボールとの接触(Colision)検出ができるので、タッチしたPlayer(Agent)の履歴を記録する。

・3回以上連続タッチすればドリブルとして評価する。
・連続タッチ数が高いほど高評価を与える。
・相手チーム選手の相対位置も考慮し、剥がした場合(相手を抜き去った)場合にさらに高評価を与える。
献身的守備をする選手はよいこ
・自ペナルティエリア付近で、相手が蹴った(タッチしたとき)相手とゴール両端でできる三角形の中に自分がいること。(これだけで微報酬)
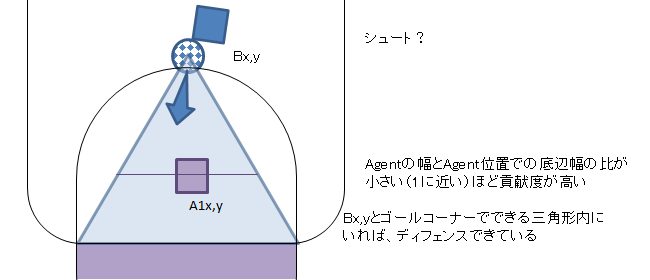
・相手がタッチした後、自分がその3角形内でボールタッチ(ディフェンスとみなす)
オウンゴールするヤツはぶっ殺す
・ゴール直前に連続して2回自チームがタッチしている
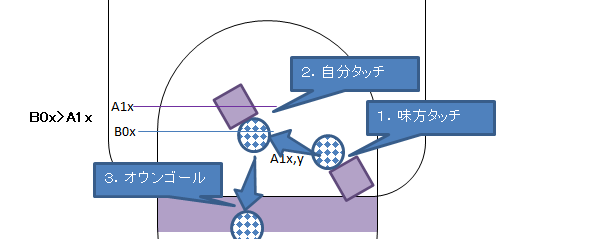
・最後にタッチしたボールの位置が自分より自ゴール側(自ゴール側へ蹴っていることに相当)
※相手シュートに対してどんなディフェンスをしてもオウンゴール罰にはしない。(ただしダブルタッチはNG)
・ノールックで守備に戻るときにボールを巻き込んでオウンゴールすることが多いが、これは学習がしにくい(ボールが見えてない)。判定が難しいので2回タッチ判定で代用する。
コーディングがまだできないので、12時間トレーニングした「わたくしたちの」左サイドブルーチームとRelease20に付属していた「バリバリトレーニング済」右サイド紫チームの対戦を御覧ください。
おどおどしたブルーチームに対して、紫チームは王者の余裕です。
トレーニングは続きます。